About the Merge
A common use case for DataWeave developers is that of merging elements from two different object collections into a set of composite output records. There are several ways to accomplish this, and we will look at a couple of them in this article.

As we explore this, we’ll also consider these ideas:
The value of meaningful symbol names
Using variables and functions to encapsulate awkward logic
Using the groupBy() function to transform an array into a handy lookup table
This article also illustrates an approach that uses iterative construction to get our solution. It also demonstrates the value of moving complex operations into variables or functions to make our body expression more readable.
[Note: The considerations here are designed to facilitate understanding of the language. Best practice with DataWeave is to refactor important phrases to make them more generalized, and thus reusable. On the other hand, during initial development (and in team development) it pays to signal intention in the code until it is ready to be refactored for reuse.]
The Code
For this experiment, we begin with a simple example that illustrates one approach to merging data from two sources..
Original Example
Here’s what we start with
var firstInput = [
{ "bookId":"101",
"title":"world history",
"price":"19.99"
},
{
"bookId":"202",
"title":"the great outdoors",
"price":"15.99"
}
]
var secondInput = [
{
"bookId":"101",
"author":"john doe"
},
{
"bookId":"202",
"author":"jane doe"
}
]
---
firstInput map (firstInputValue) ->
{
theId : firstInputValue.bookId as Number,
theTitle: firstInputValue.title,
thePrice: firstInputValue.price as Number,
(secondInput filter ($.*bookId contains firstInputValue.bookId) map (secondInputValue) -> {
theAuthor : secondInputValue.author
})
}
Here’s what we get for our effort:
[
{
"theId": 101,
"theTitle": "world history",
"thePrice": 19.99,
"theAuthor": "john doe"
},
{
"theId": 202,
"theTitle": "the great outdoors",
"thePrice": 15.99,
"theAuthor": "jane doe"
}
]
To be fair, this is code merely meant to demonstrate a pattern. But it gives us an opportunity to consider a little bit about style in our code. In this example, we can find a number of opportunities for improvement.
The example uses abstract variable names that leave it without a strong context. Its more difficult to read, and its point is more easily overlooked
The meaningful part of the expression uses a filter lambda with default symbols as its input parameters. That makes it harder to understand the expression
The data is merged inside one complex expression (a map() call against an array created by the filter() call, itself inside another map() call). This makes it difficult to observe intermediate results as we construct our transformation.
Here are some things we can do to improve this code.
Alter the variable names to give them some context. With well chosen symbol names, we can more readily see the logic that does the trick.
Consider the use of the groupBy() function to simplify the expression that merges the data.
Move the lookup logic into a function of its own, further simplifying the body expression
Let’s begin by seeing the effect of making the first two changes.
With Rational Names
An argument could be made about the clarity of the expression that does the work here:
(secondInput filter ($.*bookId contains firstInputValue.bookId) map (secondInputValue) -> {
theAuthor : secondInputValue.author
})
While this is somewhat readable and certainly does the work, one must understand the meaning or purpose of both arrays in use here to understand this snippet. The names fail to communicate any context where one is clearly available. For example, if this snippet is seen in isolation, how would we discern that “secondInput” is a collection of author records, and that “firstInputValue” is a specific book record? While that insight is available just a few lines of code away in our example, even a bit more complexity in the surrounding context would obscure those facts.
By supplying useful symbol names for our variables, we can much more easily see the effect of the relevant expression. With that done, we can also simplify the expression that merges the data.
var books = [...
var authors = [...
---
books map (aBook) ->
{
theId : aBook.bookId as Number,
theTitle: aBook.title,
thePrice: aBook.price as Number,
theAuthor: {((authors groupBy $.bookId)."$(aBook.bookId)")}.author, // alternate approach
}
One might argue that this is more than just a matter of taste. With symbol names that provide context, we can more easily understand the expressions in the body. Furthermore, by producing a transformed version of the “authors” collection, we can select just the element we need.
The original expression uses a filter to eliminate all the elements of the “authors” collection leaving only the one we seek. Instinctively it seems more efficient to use a selector to get what we need rather than calling the filter() function with an expression that might be called confusing.
Consider this conceptualization of the competing approaches:
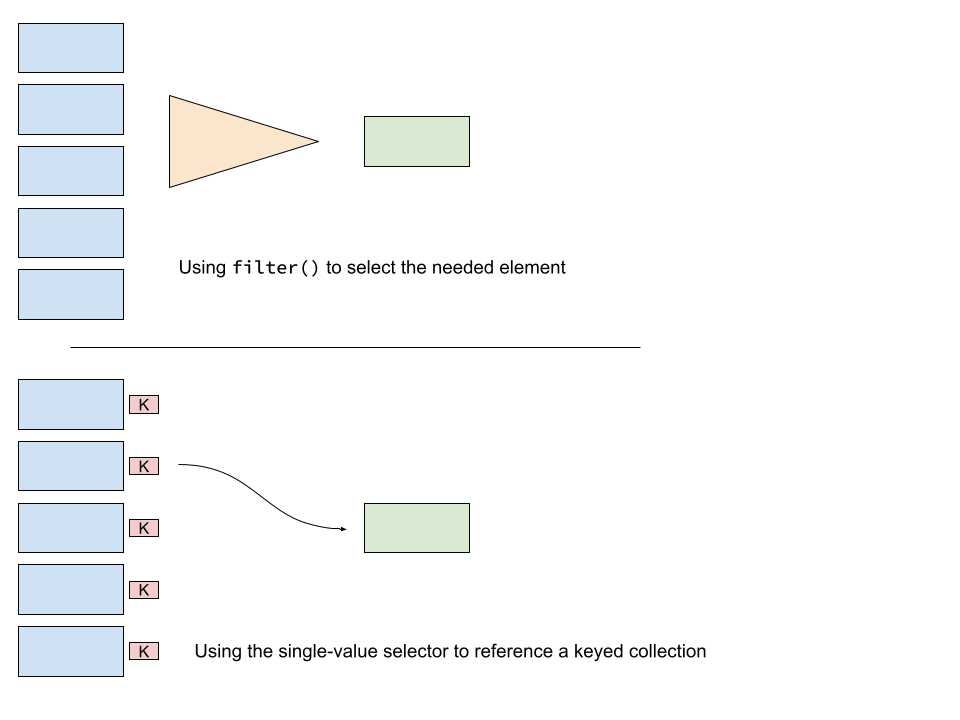
From a performance standpoint now, we might imagine that the groupBy() call to establish the keyed collection will happen once and then precise references can be made. On the other hand, the filter lambda must be interpreted once for each element of the reference collection.
Using a Variable and a Function
A further improvement would be to tuck the transformation of the “authors” collection into a variable, and to move the actual lookup into a function.
The variable definition looks like this:
var authorIndex = authors groupBy $.bookId
And here’s what we get for that:
{
"101": [
{
"bookId": "101",
"author": "john doe"
}
],
"202": [
{
"bookId": "202",
"author": "jane doe"
}
]
}
So now, we can simply select an author entry by providing the book ID as a key:
authorIndex."101"
This gives us:
[
{
"bookId": "101",
"author": "john doe"
}
]
There are two good ways to eliminate the surrounding array:
authorIndex."101"[0]
Or:
{(authorIndex."101")}
The first expression may be easier to grasp at a glance. By using the index selector [] we can easily refer to “the first element of authorIndex.’101’”
The second variation uses the evaluation parenthesis () to extract all key value pairs from the array, and the object constructor {} places them into an explicit new object.
In either case, the resulting structure is this:
{
"bookId": "101",
"author": "john doe"
}
Now, we can write a function to look up the entry for the correct author. That will simplify our logic in the body expression. Here is the function:
fun lookupAuthor (bookID:String) =
authorIndex[bookID][0].author
And that allows us to use this expression in the body:
books map (aBook) -> {
theId : aBook.bookId as Number,
theTitle: aBook.title,
thePrice: aBook.price as Number,
theAuthor: lookupAuthor(aBook.bookId)
}
Our body expression is now much more presentable, but there is another benefit from our revised approach. The variable we’ve created for the lookup table is available to inspect in isolation. We could, for instance, temporarily add a new element to the object that displays our variable. The same could be said of the results from our function. We can call the function with static input to test its accuracy.
Constructing a DataWeave transformation by using small, testable steps will allow us to observe intermediate results. While it might seem that the primary value of this approach occurs during development time, we should consider that it also offers advantages when it comes to testing, maintenance, and observation of performance metrics.
Should we wish to compare the performance of the original approach with our revised approach, having each alternative available as a function makes it possible to observe the difference.
Conclusion
These are just two examples of DataWeave code that will achieve our goal of merging fields from two different objects. There are a number of other ways we might get the job done. The dw::core::Arrays::join() function can be used to combine elements from two different arrays using selection criteria we provide as a lambda. The update operator can be used to add elements to an object, suggesting an approach similar to what we did here.
To learn more about those functions, or about DataWeave in general, be sure to check out the DataWeave Playground (https://developer.mulesoft.com/learn/dataweave/playground) or register yourself to attend the Instructor Led training. (https://training.mulesoft.com/course/development-dataweave-mule4) You’ll find lots of hands-on opportunity when you get there.



No comments:
Post a Comment